House Price Prediction
Machine learning model to predict house prices using data analysis and predictive modeling techniques.
Project Overview
The House Price Prediction project implements various machine learning models to predict the sale prices of residential homes based on features like location, size, condition, and amenities. This project explores different regression techniques to find the most accurate prediction model.
The goal is to help homeowners, real estate agents, and investors estimate property values accurately by analyzing relevant housing market data. This project demonstrates the application of data science in solving real-world problems in the real estate domain.
Technologies Used:
Key Features
Comprehensive Data Analysis
Thorough exploration and visualization of housing data to identify patterns, correlations, and important features that impact house prices.
Data Preprocessing Pipeline
Robust data cleaning, handling missing values, outlier removal, and feature engineering to improve model performance.
Multiple ML Algorithms
Implementation of various machine learning models including linear regression, decision trees, random forests, gradient boosting, and neural networks.
Model Evaluation & Comparison
Comprehensive evaluation of model performance using metrics like RMSE, MAE, and R² with cross-validation for reliable results.
Project Workflow
Data Collection & Preparation
The project begins with acquiring a comprehensive dataset of housing information. The Ames Housing dataset contains extensive information on residential properties, including features like the size, quality, condition, amenities, and sale prices. The data is loaded and inspected to understand its structure and identify any initial issues.
Exploratory Data Analysis
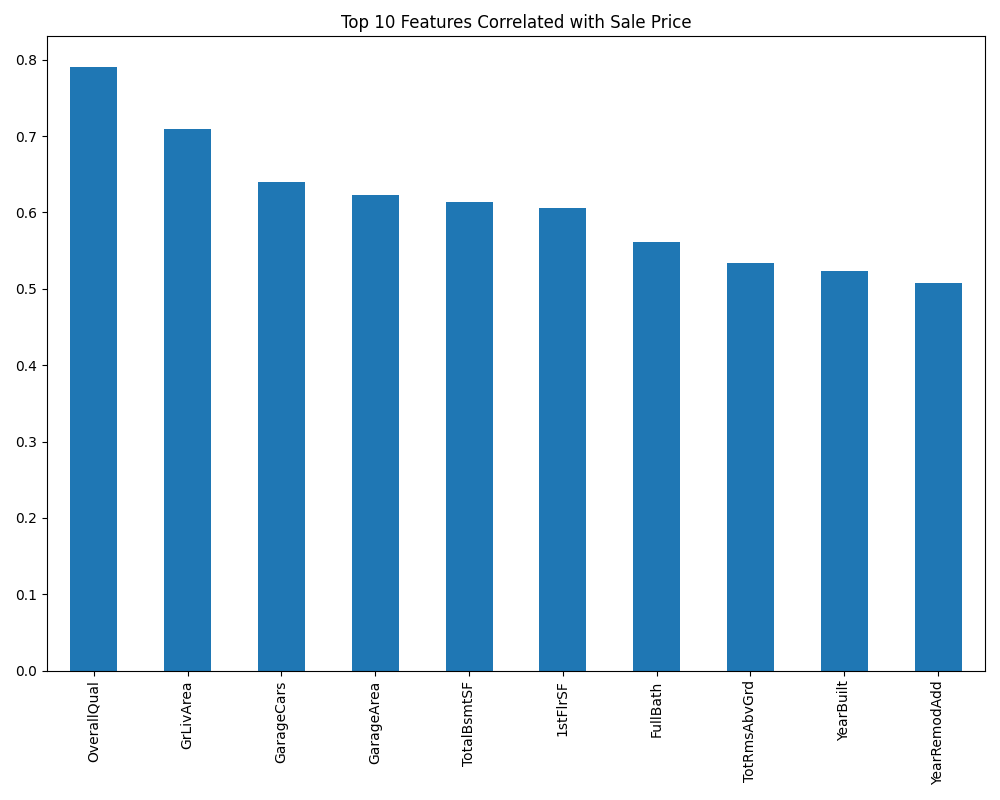
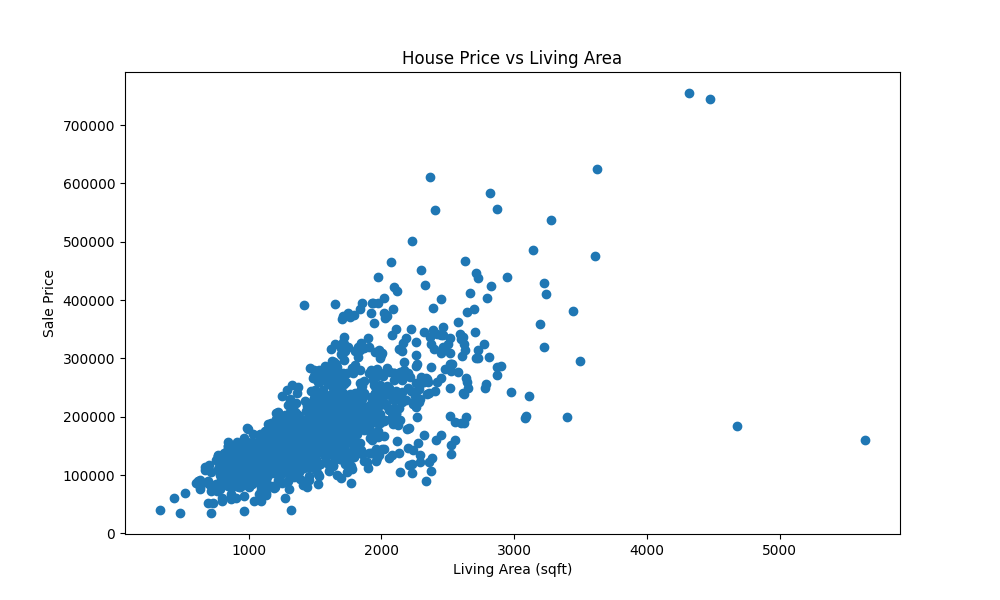
Thorough analysis of the dataset is conducted to gain insights into the distribution of variables, identify correlations, and detect patterns. This phase includes statistical analysis and data visualization to understand how different features relate to house prices. Key features with strong correlations to the target variable are identified.
Data Preprocessing
The data undergoes thorough preprocessing to ensure quality and suitability for model training. This includes handling missing values through imputation techniques, removing outliers, encoding categorical variables, and feature engineering to create new informative attributes. Feature scaling is applied where necessary to normalize the data.
Model Development
Multiple machine learning models are implemented and trained on the preprocessed data. The project explores various algorithms including linear regression, decision trees, random forests, gradient boosting methods like XGBoost, and neural networks. Each model is fine-tuned by optimizing hyperparameters to maximize predictive performance.
Evaluation & Validation
The models are rigorously evaluated using metrics such as Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), and coefficient of determination (R²). Cross-validation techniques ensure reliable performance assessment. The models are compared to determine which provides the most accurate predictions of house prices.
Feature Importance Analysis
Analysis of feature importance identifies which housing characteristics have the strongest influence on price predictions. This provides valuable insights for homeowners and real estate professionals about which aspects of a property contribute most significantly to its market value.
Project Gallery